
متاآنالیز یا فراتحلیل: کاربردی ترین راهنما
819 Views
متاآنالیز چیست؟
متاآنالیز یک روش آماری است که برای ترکیب و ترکیب یافتههای چندین مطالعه مستقل برای تخمین اندازه اثر میانگین برای یک سؤال تحقیق خاص استفاده میشود.
فراتحلیل فراتر از مرورهای روایی سنتی بوده که از روشهای آماری برای ادغام نتایج چندین مطالعه استفاده می کند و منجر به ارزیابی عینیتر شواهد میشود.
این روش محدودیتهایی مانند حجم نمونه کوچک در مطالعات فردی را برطرف میکند و تخمین دقیقتری از اثر درمان یا قدرت رابطه ارائه میدهد.
همانطور که در مثال مکمل ویتامین D و پیشگیری از شکستگی دیده می شود، متاآنالیزها به ویژه زمانی ارزشمند هستند که نتایج مطالعه فردی غیرقطعی یا متناقض باشد. به عنوان مثال، یک متاآنالیز در JAMA در سال 2017 توسط ژائو و همکاران منتشر شد. 81 کارآزمایی تصادفیسازی و کنترلشده شامل 53537 شرکتکننده را مورد بررسی قرار داد. نتایج این متاآنالیز نشان داد که مکمل ویتامین D با خطر کمتر شکستگی در میان بزرگسالان ساکن جامعه ارتباطی ندارد. این یافته با برخی باورهای قبلی و نتایج مطالعات فردی که یک اثر محافظتی را پیشنهاد کرده بودند، در تضاد بود.
تفاوت بین متاآنالیز، مرور سیستماتیک و مرور ادبیات چیست؟
بررسی ادبیات می تواند بدون رویه های تعریف شده برای جمع آوری اطلاعات انجام شود. بررسیهای سیستماتیک از پروتکلهای سختگیرانه برای به حداقل رساندن سوگیری در هنگام جمعآوری و ارزیابی مطالعات استفاده میکنند و آنها را شفافتر و قابل تکرارتر میسازد.
در حالی که یک مرور سیستماتیک به طور کامل یک زمینه تحقیقاتی را ترسیم می کند، نمی تواند اطلاعات بی طرفانه ای در مورد بزرگی یک اثر ارائه دهد.
متاآنالیز از نظر آماری اندازههای اثر مطالعات مشابه را ترکیب میکند و با وزن دادن به هر مطالعه بر حسب دقت آن، یک گام فراتر از مرور سیستماتیک پیش میرود.
اندازه اثر چیست؟
اهمیت آماری، معیار ضعیفی در متاآنالیز است زیرا فقط نشان می دهد که آیا یک اثر احتمالاً تصادفی رخ داده است یا خیر. اما اطلاعاتی در مورد بزرگی یا اهمیت عملی اثر ارائه نمی دهد.
در حالی که یک نتیجه آماری معنی دار ممکن است اثری متفاوت از صفر را نشان دهد، این اثر ممکن است عملا ارزش عملی نداشته باشد. از سوی دیگر، اندازه اثر، معیار استاندارد شدهای از بزرگی اثر را ارائه میدهد و امکان تفسیر معنادارتری از یافتهها را فراهم میکند.
متاآنالیز فراتر از سنتز اندازه های اثر است. از این آمار برای ارائه میانگین وزنی اندازه اثر از مطالعاتی که به سؤالات تحقیقاتی مشابه می پردازند استفاده می کند. هر چه اندازه اثر بزرگتر باشد، رابطه بین دو متغیر قوی تر است.
اگر اندازه اثرها منسجم باشد، تجزیه و تحلیل نشان میدهد که یافتهها در مطالعات واردشده قوی هستند. هنگامی که در اندازه اثر تفاوت وجود دارد، محققان باید به جای گزارش یک اثر خلاصه، بر درک دلایل این پراکندگی تمرکز کنند.
متارگرسیون یکی از روشهای بررسی این تنوع با بررسی رابطه بین اندازه اثر و ویژگیهای مطالعه است.
سه خانواده اصلی از اندازه اثر وجود دارد که در اکثر متاآنالیزها استفاده می شود:
- اندازههای اثر تفاوت میانگین: برای نشان دادن میزان تفاوت بین میانگینهای گروهها یا شرایط استفاده میشود که معمولاً هنگام مقایسه یک گروه درمان و گروه کنترل استفاده میشود.
- اندازه های اثر همبستگی: نشان دهنده میزان ارتباط بین دو معیار پیوسته است که قدرت و جهت رابطه آنها را نشان می دهد.
- اندازههای اثر نسبت شانس: برای مقایسه احتمال وقوع یک رویداد بین دو گروه استفاده میشود، مانند اینکه آیا بیمار از یک بیماری بهبود مییابد یا خیر.
- برآورد تأثیر کلی مداخلات ذهنیت رشد بر پیشرفت تحصیلی دانشآموزان مقطع ابتدایی و راهنمایی.
- برای بررسی اینکه آیا تأثیر مداخلات ذهنیت رشد بر پیشرفت تحصیلی برای دانش آموزان در سنین مختلف متفاوت است (به عنوان مثال، دانش آموزان دبستانی در مقابل دانش آموزان دبیرستانی).
- بررسی اینکه آیا مدت مداخله ذهنیت رشد بر اثربخشی آن تأثیر می گذارد یا خیر.
- مداخلات ذهنیت رشد تأثیر مثبت کوچک، اما از نظر آماری معناداری بر پیشرفت تحصیلی دانش آموزان خواهد داشت.
- مداخلات ذهنیت رشد برای دانش آموزان جوان تر از دانش آموزان مسن تر موثرتر خواهد بود.
- مداخلات ذهنی رشد طولانی تر از مداخلات کوتاه تر موثرتر خواهد بود.
- مطالعات منتشر شده در مجلات انگلیسی زبان.
- مطالعات باید شامل معیار کمی برای پیشرفت تحصیلی باشد (مثلاً معدل، نمرات دوره، نمرات امتحان یا نمرات آزمون استاندارد).
- مطالعات باید شامل مداخله ذهنیت رشد به عنوان تمرکز اصلی (شامل مقایسه گروه کنترل در مقابل درمان) باشد.
- مطالعاتی که آموزش ذهنیت رشد را با سایر مداخلات (مانند آموزش مهارتهای مطالعه، سایر انواع مداخلات روانشناختی) ترکیب میکنند، باید کنار گذاشته شوند.
- ERIC
- PsycInfo
- PubMed
- زنجیره استناد: بررسی فهرست های مرجع مطالعات گنجانده شده می تواند مقالات مرتبط دیگری را کشف کند.
- تماس با کارشناسان: ارتباط با محققان در زمینه ذهنیت رشد می تواند مطالعات منتشر نشده یا تحقیقات در حال انجام را نشان دهد.
- اندازه نمونه
- سن شرکت کنندگان
- مدت مداخله
- نوع نتیجه تحصیلی اندازه گیری شده
- طراحی مطالعه (به عنوان مثال، کارآزمایی کنترل شده تصادفی، شبه آزمایشی)
- محققان یک اندازه اثر (به عنوان مثال، تفاوت میانگین استاندارد شده) را برای هر مطالعه محاسبه خواهند کرد.
- محققان از یک مدل اثرات تصادفی برای محاسبه تنوع در اندازه اثر در مطالعات استفاده خواهند کرد.
- محققان از متارگرسیون برای آزمایش فرضیههای تعدیلکنندههای تأثیر مداخلات ذهنیت رشد استفاده خواهند کرد.
- چک لیست: PRISMA دارای یک چک لیست 27 موردی است که تمام جنبه های یک متاآنالیز، از منطق و اهداف گرفته تا ترکیب یافته ها و بحث در مورد محدودیت ها را پوشش می دهد. هر مورد چک لیست با توصیه های گزارش دقیق در یک سند توضیح و تفصیل همراه است.
- نمودار جریان یا فلودیاگرام: PRISMA همچنین شامل یک نمودار جریان برای نشان دادن بصری فرآیند انتخاب مطالعه است، که روشی شفاف و استاندارد شده برای نشان دادن چگونگی رسیدن محققان به مجموعه نهایی مطالعات گنجانده شده ارائه میکند.
- چگونه نگرش های ناکارآمد و تفکر خودکار منفی به طور مستقیم و غیرمستقیم بر افسردگی تأثیر می گذارد؟
- آیا مداخلات ذهنیت رشد به طور کلی پیشرفت تحصیلی دانش آموزان را بهبود می بخشد؟
- ارتباط بین دلبستگی کودک و والدین و اجتماعی بودن در کودکان چیست؟
- رابطه عوامل خطر مختلف با اختلال استرس پس از سانحه (PTSD) چیست؟
- پایگاه های داده: جستجوها باید شامل هفت پایگاه داده کلیدی باشند (برای روان شناسی): CINAHL، Medline، APA PsycArticles، Psychology and Behavioral Sciences Collection، APA PsycInfo، SocINDEX با متن کامل، و Web of Science: Core Collections.
- ادبیات خاکستری: علاوه بر پایگاههای اطلاعاتی، میتوان جستجوهای پزشکی قانونی یا «توسعه دهنده» را انجام داد. این شامل: جستجوهای پایگاه داده ادبیات خاکستری (به عنوان مثال OpenGrey، WorldCat، Ethos)، مجموعه مقالات کنفرانس، گزارش های منتشر نشده، پایان نامه ها، پایگاه داده های کارآزمایی بالینی، جستجو بر اساس نام نویسندگان انتشارات مربوطه. نهادهای تحقیقاتی مستقل نیز ممکن است منابع خوبی از مواد باشند، به عنوان مثال. مرکز تحقیقات در روابط قومی، بنیاد جوزف راونتری، Carers UK.
- جستجوی استناد: فهرستهای مرجع اغلب به مقالاتی با استناد بالا و تأثیرگذار در این زمینه منجر میشوند که زمینه و اطلاعات پیشزمینه ارزشمندی را برای بررسی فراهم میکنند.
- تماس با کارشناسان: تماس با محققان یا متخصصان در این زمینه می تواند دسترسی به داده های منتشر نشده یا تحقیقات در حال انجام را که هنوز در دسترس عموم نیست، فراهم کند.
- ویژگیهای مداخله: محققان ممکن است تصمیم بگیرند که برای اینکه در مرور لحاظ شود، یک مداخله باید ویژگیهای خاصی داشته باشد. آنها ممکن است نیاز داشته باشند که مداخله برای مدت معینی دوام داشته باشد، یا ممکن است تشخیص دهند که فقط مداخلات با مبنای نظری خاص برای بررسی آنها مناسب است.
- ویژگی های جمعیت: یک متاآنالیز ممکن است بر اثرات یک مداخله برای یک جمعیت خاص متمرکز شود. به عنوان مثال، محققان ممکن است بر روی مطالعاتی تمرکز کنند که فقط شامل پرستاران یا پزشکان میشود.
- اندازهگیریهای پیامد: محققان ممکن است فقط مطالعاتی را بگنجانند که از معیارهای نتیجهای استفاده میکنند که استاندارد خاصی را برآورده میکنند.
- سن شرکتکنندگان: اگر یک متاآنالیز اثرات یک درمان یا مداخله را برای کودکان بررسی کند، نویسندگان مرور احتمالاً هرگونه مطالعهای را که شامل کودکان در محدوده سنی مورد نظر نبوده است، حذف خواهند کرد.
- وضعیت تشخیصی شرکتکنندگان: محققانی که یک متاآنالیز از درمانهای اضطراب را انجام میدهند، احتمالاً هر مطالعهای را که در آن شرکتکنندگان با اختلال اضطراب تشخیص داده نشده بودند، کنار میگذارند.
- طراحی مطالعه: محققان ممکن است تشخیص دهند که فقط مطالعاتی که از یک طرح تحقیقاتی خاص استفاده میکنند، مانند کارآزمایی تصادفیسازی و کنترلشده، در مرور گنجانده میشوند.
- گروه کنترل: در یک متاآنالیز یک مداخله، محققان ممکن است انتخاب کنند که فقط مطالعاتی را شامل انواع خاصی از گروههای کنترل، مانند کنترل لیست انتظار یا نوع دیگری از مداخله، بگنجانند.
- وضعیت انتشار: تصمیم بگیرید که آیا فقط مطالعات منتشر شده شامل می شود یا اینکه آیا آثار منتشر نشده مانند پایان نامه ها یا مجموعه مقالات کنفرانس نیز در نظر گرفته می شود.
- تدوین استراتژی اولیه: بر اساس سوال تحقیق، تیم یک استراتژی جستجوی مقدماتی شامل شناسایی کلمات کلیدی مرتبط، مترادف ها، پایگاه های داده و محدودیت های جستجو را توسعه می دهد.
- جستجوها و اصلاحات آزمایشی: استراتژی جستجوی اولیه سپس بر روی پایگاه های داده انتخاب شده آزمایش می شود. نتایج از نظر ارتباط بررسی می شوند و استراتژی جستجو بر این اساس اصلاح می شود. این ممکن است شامل افزودن یا اصلاح کلمات کلیدی، تنظیم عملگرهای بولی یا بازنگری در پایگاه های داده استفاده شده باشد.
- بحث و تکرار: نتایج جستجو و اصلاحات پیشنهادی در تیم بررسی مورد بحث قرار می گیرد. تیم به طور مشترک بهترین اصلاحات را برای بهبود جامعیت و ارتباط جستجو تصمیم می گیرد.
- تکرار چرخه: این چرخه از جستجوهای آزمایشی، تجزیه و تحلیل، بحثها و اصلاحات تکرار میشود تا زمانی که تیم از توانایی استراتژی برای گرفتن همه مطالعات مرتبط و به حداقل رساندن نتایج نامربوط راضی شود.
- غربالگری اولیه عناوین و چکیده ها: پس از اعمال استراتژی برای جستجوی ادبیات، گام بعدی شامل غربالگری عناوین و چکیده مقالات شناسایی شده بر اساس معیارهای ورود و خروج از پیش تعریف شده است. در طول این غربالگری اولیه، هدف بازبینان شناسایی مطالعات مرتبط بالقوه در حالی که آنهایی را که به وضوح خارج از محدوده بازبینی هستند حذف میکنند. اولویت بندی بیش از حد در این مرحله بسیار مهم است، به این معنی که بازبینان باید در سمت حفظ مطالعات اشتباه کنند، حتی اگر در مورد ارتباط آنها عدم اطمینان وجود داشته باشد. این رویکرد محتاطانه به به حداقل رساندن خطر حذف ناخواسته مطالعات بالقوه ارزشمند کمک می کند.
- بازیابی و ارزیابی متون کامل: برای مطالعاتی که نمی توان تنها بر اساس عنوان و چکیده تصمیم قطعی گرفت، داوران باید متن کامل مقالات را برای ارزیابی جامع بر اساس معیارهای از پیش تعریف شده ورود و خروج به دست آورند. این مرحله شامل بررسی دقیق متن کامل هر مطالعه مرتبط بالقوه برای تعیین واجد شرایط بودن آن است.
- حل اختلافات: در موارد اختلاف نظر بین داوران در مورد واجد شرایط بودن یک مطالعه، یک استراتژی از پیش تعریف شده شامل بحث های اجماع سازی یا داوری توسط بازبین سوم باید برای رسیدن به تصمیم نهایی وجود داشته باشد. این رویکرد مشارکتی فرآیند انتخاب منصفانه و بیطرفانه را تضمین میکند و قابلیت اطمینان بازبینی را بیشتر تقویت میکند.
- شناسایی: تعداد اولیه عناوین و چکیده های شناسایی شده از طریق جستجو در پایگاه داده.
- غربالگری: فرآیند نمایش بر اساس عناوین و چکیده ها.
- واجد شرایط بودن: نسخه های متن کامل سوابق باقی مانده بازیابی شده و برای واجد شرایط بودن ارزیابی می شوند.
- ورود (Inclusion): بکارگیری معیارهای ورود از پیش تعریف شده منجر به گنجاندن نشریاتی شد که تمامی معیارهای بررسی را داشته باشند.
- خروج (Exclusion): فلوچارت دلایل حذف رکوردهای باقیمانده را شرح می دهد.
- ویژگی های مطالعه: سال انتشار، نویسندگان، کشور مبدأ، وضعیت انتشار (منتشر شده: مقالات مجلات با داوری همتا و فصل های کتاب منتشر نشده: گزارش های دولتی، وب سایت ها، پایان نامه ها/پایان نامه ها، ارائه کنفرانس ها، نسخه های خطی منتشر نشده).
- مداخله: نوع (به عنوان مثال، CBT)، مدت زمان درمان، دفعات درمان (به عنوان مثال، جلسات هفتگی)، روش زایمان (به عنوان مثال، فردی، گروهی، آنلاین)، تجزیه و تحلیل قصد درمان (بله/خیر)
- اندازهگیریهای پیامد: پیامدهای اولیه در مقابل پیامدهای ثانویه، نقاط زمانی اندازهگیری (به عنوان مثال، پس از درمان، پیگیری).
- مدراتورها: ویژگی های شرکت کننده که ممکن است اندازه اثر را تعدیل کند. (به عنوان مثال، سن، جنسیت، تشخیص، وضعیت اجتماعی-اقتصادی، سطح تحصیلات، بیماری های همراه).
- طراحی مطالعه: طراحی (شبه آزمایش RCT و غیره)، کور کردن، گروه کنترل استفاده شده (به عنوان مثال، کنترل لیست انتظار، درمان طبق معمول)، محیط مطالعه (بالینی، اجتماعی، آنلاین/از راه دور، بستری در مقابل سرپایی)، پیش ثبت نام (بله/خیر)، روش تخصیص (تصادفی سازی ساده، تصادفی سازی بلوکی و غیره).
- نمونه: روش استخدام (گلوله برفی، تصادفی، و غیره)، حجم نمونه (کل و گروه)، محل نمونه (گروه درمان و کنترل)، میزان ساییدگی، همپوشانی با نمونه(های) مطالعه دیگری؟
- پایبندی به دستورالعمل های گزارش دهی: به عنوان مثال، CONSORT، STROBE، PRISMA
- منبع تامین مالی: دولتی، صنعتی، غیر انتفاعی و غیره.
- اندازه اثر: برنامه فرا تحلیل جامع برای محاسبه d و/یا r استفاده می شود. حداکثر 3 رقم بعد از نقطه اعشار برای اطلاعات اندازه اثر و اطلاعات سازگاری داخلی قرار دهید. همچنین شماره صفحه و شماره جدولی که اطلاعات از آن کدگذاری شده است را ثبت کنید. این اطلاعات به هنگام بررسی قابلیت اطمینان و دقت کمک می کند تا مطمئن شویم که از همان اطلاعات کدنویسی می کنیم.
- توسط Cochrane Collaboration برای ارزیابی کارآزماییهای تصادفیسازی و کنترلشده (RCT) توصیه شده است.
- سوگیری های احتمالی را در انتخاب، عملکرد، تشخیص، ساییدگی و گزارش ارزیابی می کند.
- برای ارزیابی کیفیت مطالعات غیر تصادفی، از جمله مطالعات مورد شاهدی و کوهورت استفاده می شود.
- انتخاب، مقایسه و ارزیابی نتیجه را ارزیابی می کند.
- خطر سوگیری را در مطالعات غیر تصادفی مداخلات ارزیابی می کند.
- مخدوشگرها، سوگیری انتخاب، طبقه بندی مداخلات، انحراف از مداخلات مورد نظر، داده های از دست رفته، اندازه گیری نتایج، و انتخاب نتایج گزارش شده را ارزیابی می کند.
- به طور خاص برای مطالعات دقت تشخیصی طراحی شده است.
- خطر سوگیری و نگرانیهای کاربردی را در انتخاب بیمار، آزمون شاخص، استاندارد مرجع، و جریان و زمانبندی ارزیابی میکند.
- نسبت شانس (OR): برای مثال، اگر محققان در علوم پزشکی و بهداشتی کار می کنند که در آن نتایج باینری رایج است (به عنوان مثال، بله/خیر، شکست/موفقیت)، معمولاً از اندازه های تأثیر مانند خطر نسبی و نسبت شانس استفاده می شود.
- تفاوت میانگین: مطالعاتی که بر مقایسه های تجربی یا بین گروهی تمرکز می کنند، اغلب از تفاوت های میانگین استفاده می کنند. تفاوت میانگین خام یا تفاوت میانگین غیر استاندارد زمانی مناسب است که مقیاس اندازه گیری ذاتاً معنی دار و قابل مقایسه در بین مطالعات باشد.
- تفاوت میانگین استاندارد شده (SMD): اگر مطالعات از مقیاس ها یا معیارهای متفاوتی استفاده می کنند، تفاوت میانگین استاندارد شده (مثلاً d کوهن) مناسب تر است. هنگام تجزیه و تحلیل مطالعات مشاهده ای، ضریب همبستگی معمولاً به عنوان اندازه اثر انتخاب می شود.
- ضریب همبستگی پیرسون (r): یک معیار آماری که اغلب در متاآنالیز برای بررسی قدرت رابطه بین دو متغیر پیوسته استفاده می شود.
- آزمون همگنی: متاآنالیزها معمولاً شامل یک آزمون همگنی میشوند تا تعیین کنند که آیا اندازههای اثر همان پارامتر جمعیت را تخمین میزنند یا خیر. آماره آزمون که با Q نشان داده می شود، مجموع وزنی مربع هاست که از توزیع کای دو پیروی می کند. یک آمار Q قابل توجه نشان می دهد که اندازه اثر ناهمگن است.
- آماره I2: آماره I2 اندازه گیری نسبی ناهمگونی است که نشان دهنده نسبت واریانس بین مطالعه (τ2) به کل واریانس (واریانس بین مطالعه به اضافه واریانس درون مطالعه) است. مقادیر I2 بالاتر نشان دهنده ناهمگنی بیشتر است.
- فاصله پیش بینی: بررسی عرض یک بازه پیش بینی می تواند بینشی در مورد درجه ناهمگنی ارائه دهد. یک فاصله پیشبینی گسترده نشاندهنده ناهمگونی قابلتوجهی در اندازه اثر جمعیت است.
- فرض میکند که همه مطالعات دقیقاً یک چیز را اندازهگیری میکنند
- به مطالعات بزرگتر وزن بسیار بیشتری می دهد
- زمانی استفاده کنید که مطالعات بسیار مشابه هستند
- سادگی: پیاده سازی و تفسیر مدل اثر ثابت ساده است و از نظر محاسباتی ساده تر می شود.
- دقت: زمانی که فرض یک اندازه اثر مشترک برآورده شود، مدلهای اثر ثابت تخمینهای دقیقتری را با فواصل اطمینان باریکتر در مقایسه با مدلهای اثرات تصادفی ارائه میکنند.
- مناسب برای استنباط های مشروط: مدل های اثر ثابت زمانی مناسب هستند که هدف، استنتاج به طور خاص در مورد مطالعات موجود در متاآنالیز باشد، بدون تعمیم به جمعیت گسترده تر.
- مفروضات محدود کننده: مدل اثر ثابت فرض میکند که همه مطالعات پارامتر جمعیتی یکسانی را تخمین میزنند، که اغلب غیرواقعی است، بهویژه با مطالعاتی که از روشها یا جمعیتهای مختلف گرفته شدهاند.
- تعمیم پذیری محدود: یافته های مدل های اثر ثابت مشروط به مطالعات وارد شده است و قابلیت تعمیم آن ها را به بافت ها یا جمعیت های دیگر محدود می کند.
- حساسیت به ناهمگنی: مدلهای اثر ثابت به وجود ناهمگنی در میان مطالعات حساس هستند و در صورت وجود ناهمگنی قابلتوجه ممکن است نتایج گمراهکنندهای ایجاد کنند.
- فرض می کند مطالعات ممکن است چیزهای کمی متفاوت را اندازه گیری کنند
- به مطالعات بزرگ و کوچک وزن متعادل تری می دهد
- زمانی استفاده کنید که مطالعات ممکن است در روش ها یا جمعیت متفاوت باشد
- مفروضات واقع بینانه: مدل های اثرات تصادفی وجود تنوع بین مطالعات را با فرض اینکه اثرات واقعی به طور تصادفی توزیع شده اند تأیید می کنند و آن را برای سناریوهای تحقیقاتی در دنیای واقعی مناسب تر می کند.
- تعمیمپذیری: مدلهای اثرات تصادفی امکان استنباط گستردهتری را درباره جمعیتی از مطالعات فراهم میکنند و تعمیمپذیری یافتهها را افزایش میدهند.
- تطبیق ناهمگونی: مدلهای اثرات تصادفی به صراحت ناهمگونی را مدلسازی میکنند و زمانی که مطالعات دارای اندازههای اثر متفاوت هستند، نمایش دقیقتری از اثر کلی ارائه میدهند.
- پیچیدگی: مدلهای اثرات تصادفی از نظر محاسباتی پیچیدهتر هستند و به تخمین پارامترهای اضافی مانند واریانس بین مطالعه نیاز دارند.
- دقت کاهشیافته: فواصل اطمینان در مقایسه با مدلهای اثر ثابت گستردهتر است، بهویژه زمانی که ناهمگونی بین مطالعات قابل توجه است.
- نیاز به مطالعات کافی: برآورد دقیق واریانس بین مطالعات مستلزم تعداد کافی مطالعه است، که باعث می شود مدل های اثرات تصادفی با متاآنالیزهای کوچکتر قابل اعتمادتر نباشند.
- وزن هر مطالعه را محاسبه کنید
- تأثیر هر مطالعه را در وزن آن ضرب کنید
- تمام این اثرات وزنی را جمع کنید
- تقسیم بر مجموع همه اوزان
- مطالعات بزرگتر (با واریانس کمتر در مطالعه) به طور قابل ملاحظه ای وزن بیشتری دریافت می کنند.
- این مدل فرض می کند که تفاوت بین نتایج مطالعه تنها به دلیل خطای نمونه گیری است.
- زمانی مناسب تر است که مطالعات در روش ها و ویژگی های نمونه بسیار مشابه باشند.
- وزن ها بین مطالعات بزرگ و کوچک در مقایسه با مدل اثرات ثابت متعادل تر است.
- زمانی مناسبتر است که مطالعات در روشها، ویژگیهای نمونه یا سایر عواملی که ممکن است بر اندازه اثر واقعی تأثیر بگذارد متفاوت باشد.
- مدل اثرات تصادفی معمولاً فواصل اطمینان گستردهتری را ایجاد میکند که منعکس کننده عدم قطعیت اضافی ناشی از تنوع بین مطالعه است.
- نتایج قابل تعمیم به جمعیت وسیع تری از مطالعات فراتر از آنهایی هستند که در متاآنالیز گنجانده شده اند.
- این مدل اغلب برای علوم اجتماعی و رفتاری واقع بینانه تر است، جایی که اثرات واقعی ممکن است در زمینه ها یا جمعیت های مختلف متفاوت باشد.
- ارزیابی تاثیر روشهای آماری مختلف: تحلیل حساسیت میتواند شامل محاسبه اثر کلی با استفاده از روشهای آماری مختلف، مانند مدلهای اثرات ثابت و تصادفی باشد. این مقایسه به تعیین اینکه آیا مدل آماری انتخاب شده به طور قابل توجهی بر نتایج کلی تأثیر می گذارد کمک می کند. به عنوان مثال، در متاآنالیز مسدودکنندههای بتا پس از سکته قلبی، هر دو مدل اثرات ثابت و تصادفی تخمینهای کلی تقریباً یکسانی را ارائه کردند.
این نشان می دهد که یافته های متاآنالیز نسبت به روش آماری به کار گرفته شده انعطاف پذیر هستند. - ارزیابی تأثیر کیفیت و اندازه کارآزمایی: با تجزیه و تحلیل دادهها با و بدون آزمایشهایی با کیفیت مشکوک یا اندازههای متفاوت، محققان میتوانند تأثیر این عوامل را بر یافتههای کلی ارزیابی کنند.
- بررسی تأثیر کارآزماییهایی که زودتر متوقف شدهاند: شامل کارآزماییهایی که به دلیل نتایج تحلیل موقت زود متوقف شدهاند، میتواند سوگیری را ایجاد کند. تجزیه و تحلیل حساسیت به تعیین اینکه آیا گنجاندن یا حذف چنین کارآزمایی ها به طور قابل توجهی تأثیر کلی را تغییر می دهد کمک می کند. در مثال متاآنالیز مسدودکننده β، حذف کارآزماییهایی که زودتر متوقف شدند تأثیر ناچیزی بر برآورد کلی داشت.
- پرداختن به سوگیری انتشار: ارزیابی و توضیح سوگیری انتشار ضروری است، که زمانی رخ میدهد که مطالعاتی با نتایج آماری معنیدار نسبت به مطالعاتی که یافتههای پوچ یا غیر معنیدار دارند، احتمال انتشار بیشتری دارند. این را میتوان با استفاده از تکنیکهایی مانند نمودارهای قیفی، آزمونهای آماری (مانند آزمون همبستگی رتبهای Begg و Mazumdar، آزمون Egger) و تحلیلهای حساسیت انجام داد.
- تعداد ناکافی مطالعات: اگر مطالعات اولیه بسیار کمی در دسترس باشد، ممکن است متاآنالیز مناسب نباشد. در حالی که یک متاآنالیز از نظر فنی می تواند تنها با دو مطالعه انجام شود، جامعه پژوهشی ممکن است یافته های مبتنی بر تعداد محدودی از مطالعات را به عنوان شواهد قابل اعتماد نبیند. تعداد کمی از مطالعات می تواند نشان دهد که زمینه تحقیق به اندازه کافی برای سنتز معنی دار بالغ نیست.
- ترکیب نامناسب مطالعات: متاآنالیزها نباید صرفاً مطالعات را بطور بی رویه ترکیب کنند. از مشکل «سیب و پرتقال» پرهیز کنید، جایی که مطالعات با اهداف، طرحها، اقدامات یا نمونههای مختلف پژوهشی بهطور نامناسب ترکیب شدهاند. چنین اقداماتی می تواند تفاوت های مهم بین مطالعات را پنهان کند و منجر به نتایج گمراه کننده شود.
- تفسیر نادرست ناهمگنی: یکی از اشتباهات رایج استفاده از آماره Q یا p-value از آزمون ناهمگنی به عنوان تنها شاخص ناهمگنی است. در حالی که این آمار می تواند نشان دهنده ناهمگونی باشد، میزان تنوع در اندازه اثر را تعیین نمی کند.
- اتکای بیش از حد به مطالعات منتشر شده: این وابستگی به ادبیات منتشر شده خطر سوگیری انتشار را معرفی می کند، جایی که مطالعات با نتایج آماری معنی دار یا مطلوب احتمال بیشتری دارد که منتشر شوند. عدم پذیرش و رسیدگی به سوگیری انتشار می تواند منجر به تخمین بیش از حد اندازه اثر واقعی شود.
- نادیده گرفتن کیفیت مطالعه: شامل مطالعات با کیفیت روششناختی ضعیف میتواند نتایج یک متاآنالیز را سوگیری کند که منجر به تخمین اندازه اثر غیرقابل اعتماد و نادرست شود. تصمیم گیری در مورد اینکه کدام مطالعات شامل شود باید بر اساس معیارهای واجد شرایط بودن از پیش تعریف شده باشد تا از کیفیت و ارتباط ترکیب اطمینان حاصل شود.
- اصرار بیش از حد روی اهمیت آماری: تأکید بیش از حد بر اهمیت آماری یک اثر کلی در حالی که اهمیت عملی آن نادیده گرفته میشود، همانطور که در مطالعات اولیه پیش می آید، در فراتحلیل اشتباهی مهم است. هم اهمیت آماری و هم بالینی یا محتوایی را در نظر می گیرد.
- تفسیر نادرست تست اهمیت در تجزیه و تحلیل های زیرگروه: هنگام مقایسه اندازه اثر در بین زیر گروه ها، صرفا مشاهده اینکه یک اثر در یک زیرگروه از نظر آماری معنی دار است اما دیگری کافی نیست. آزمایشهای رسمی با اهمیت آماری برای تفاوت تأثیرات بین زیر گروهها یا محاسبه تفاوت تأثیرات با فواصل اطمینان انجام دهید.
- نادیده گرفتن وابستگی: نادیده گرفتن وابستگی در بین اندازههای اثر، بهویژه زمانی که اندازههای اثر چندگانه از یک مطالعه استخراج میشوند، یک اشتباه است. این نظارت می تواند نرخ خطای نوع I را افزایش دهد و منجر به تخمین نادرست اندازه اثر متوسط و خطاهای استاندارد شود.
- گزارش ناکافی: عدم گزارش شفاف و جامع فرآیند متاآنالیز یک اشتباه اساسی است. یک متاآنالیز باید شامل پروتکل مکتوب دقیقی باشد که در آن سؤال تحقیق، استراتژی جستجو، معیارهای ورود و روشهای تحلیلی مشخص شود.
مناسب ترین خانواده اندازه اثر بر اساس ماهیت سوال تحقیق و متغیر وابسته تعیین می شود
نحوه انجام متاآنالیز
محققان باید یک پروتکل تحقیقاتی جامعی ایجاد کنند که اهداف و فرضیه های متاآنالیز آنها را مشخص کند.
این سند باید جزئیات خاصی را در مورد هر مرحله از فرآیند تحقیق، از جمله روش شناسایی، انتخاب، و تجزیه و تحلیل مطالعات مربوطه ارائه دهد.
برای مثال، پروتکل باید استراتژیهای جستجو را برای مطالعات مرتبط مشخص کند، از جمله اینکه آیا جستجو شامل آثار منتشر نشده میشود یا خیر.
پروتکل باید قبل از شروع فرآیند تحقیق ایجاد شود تا از شفافیت و تکرارپذیری اطمینان حاصل شود.
پروتکل تحقیق
اهداف
فرضیه ها
معیارهای واجد شرایط بودن
استراتژی جستجو
محققان پایگاه های داده زیر را جستجو خواهند کرد:
کلمات کلیدی ترکیب شده با عملگرهای بولی:
(“ذهنیت رشد” یا “نظریه های ضمنی هوش” یا “نظریه ذهنیت”) و (“مداخله” یا “آموزش” یا “برنامه”) “یا “نتایج آموزشی”)* یا “دانش آموز” یا “آموزنده*”) **
استراتژی های جستجوی اضافی:
کدگذاری مطالعات
محققان هر مطالعه را برای اطلاعات زیر کد میکنند:
تجزیه و تحلیل آماری

PRISMA
PRISMA (موارد گزارش ترجیحی برای بررسی های سیستماتیک و متاآنالیزها) نوعی دستورالعمل گزارش دهی است که برای بهبود شفافیت و کامل بودن گزارش مرور سیستماتیک طراحی شده است.
PRISMA برای مقابله با موضوع گزارش بی کیفیت ناکافی که اغلب در بررسی های سیستماتیک یافت می شود ایجاد شد.
مرحله 1: تعریف سوال تحقیق
یک سوال تحقیقاتی درست تعریف شده نقطه شروع اساسی برای هر سنتز تحقیقاتی است. سؤال تحقیق باید تصمیم گیری در مورد اینکه کدام مطالعات در متاآنالیز گنجانده شود و کدام مدل آماری مناسب ترین است را هدایت کند.
به عنوان مثال:
محققان باید یک پروتکل تحقیقاتی جامعی ایجاد کنند که اهداف و فرضیه های متاآنالیز آنها را مشخص کند.
مرحله 2: استراتژی جستجو
استراتژی های جستجوی کامل را برای همه پایگاه های داده، ثبت نام ها و وب سایت ها، از جمله فیلترها و محدودیت های استفاده شده، ارائه دهید.
استراتژی جستجو یک طرح جامع و قابل تکرار برای شناسایی تمام مطالعات تحقیقاتی مرتبط است که به یک سوال تحقیقاتی خاص می پردازد.
این رویکرد سیستماتیک برای جستجو به به حداقل رساندن سوگیری کمک می کند.
مهم است که در مورد استراتژی جستجو شفاف باشید و همه تصمیمات را برای ممیزی یا auditability مستند کنید. هدف شناسایی همه مطالعات مرتبط بالقوه برای بررسی است.
PRISMA (موارد گزارش برگزیده برای بررسی های سیستماتیک و متاآنالیزها) راهنمایی مناسب برای گزارش جستجوهای کمی ادبیات ارائه می دهد.
منابع اطلاعاتی
هدف اصلی یافتن همه مطالعات منتشر شده و منتشر نشده است که معیارهای از پیش تعریف شده سوال تحقیق را برآورده می کنند. این شامل در نظر گرفتن منابع مختلف فراتر از پایگاه داده های معمولی است.
منابع اطلاعاتی برای یک متاآنالیز میتواند شامل طیف گستردهای از منابع مانند پایگاههای اطلاعاتی علمی، ادبیات منتشر نشده، مقالات کنفرانس، کتابها و حتی مشاورههای تخصصی باشد.
همه پایگاههای اطلاعاتی، مراکز ثبت، وبسایتها، سازمانها، فهرستهای مرجع و سایر منابعی را که برای شناسایی مطالعات جستجو یا رجوع شدهاند، مشخص کنید. تاریخ آخرین جستجو یا مراجعه هر منبع را هم مشخص کنید.
یک استراتژی جستجوی جامع و سیستماتیک با کمک یک کتابدار خبره ایجاد می شود.
دقت کنید که موارد بالا ممکن است فهرست جامعی از همه پایگاه های داده بالقوه نباشد.
ساخت رشته (کلمات) جستجو
توصیه می شود برای ایجاد فهرست کاملی از عبارات جستجو برای هر مفهوم، با کارشناسان موضوع در تیم بررسی و هیئت مشاوره مشورت کنید.
برای بازیابی مرتبط ترین نتایج، از یک رشته جستجو استفاده می شود. این رشته از موارد زیر تشکیل شده است:
کلمات کلیدی: عبارات جستجو باید با سوالات تحقیق، متغیرهای کلیدی، شرکت کنندگان و طرح تحقیق مرتبط باشند. جستجوها باید شامل عبارات نمایه شده، عناوین و چکیده باشند. علاوه بر این، هر پایگاه داده دارای عبارات نمایه شده خاصی است، بنابراین یک استراتژی جستجوی هدفمند باید برای هر پایگاه داده ایجاد شود.
مترادف ها: این ها کلمات یا عباراتی با معانی مشابه با کلمات کلیدی هستند، زیرا نویسندگان ممکن است از اصطلاحات مختلفی برای توصیف مفاهیم مشابه استفاده کنند. گنجاندن مترادف ها به پوشش تغییرات در اصطلاح کمک می کند و شانس یافتن همه مطالعات مرتبط را افزایش می دهد. به عنوان مثال، یک مداخله دارویی ممکن است با نام عمومی یا یکی از چندین نام اختصاصی آن ذکر شود.
نمادهای برش: این نمادها با ثبت تغییرات یک کلمه کلیدی، جستجو را گسترش می دهند. آنها با مکان یابی هر کلمه ای که با یک ریشه خاص شروع می شود عمل می کنند. به عنوان مثال، اگر کاربری در حال تحقیق در مورد مداخلات برای سیگار کشیدن بود، ممکن است از یک نماد کوتاه برای جستجوی “smok*” برای بازیابی سوابق با کلمات “smoke”، “smoker”، “smoking” یا “smokes” استفاده کند. این می تواند با حذف نیاز به وارد کردن هر گونه تغییر کلمه در پایگاه داده، در زمان و تلاش صرفه جویی کند.
عملگرهای بولی: استفاده از عملگرهای بولی (AND/OR/NEAR/NOT) به ترکیب موثر این عبارات کمک میکند و اطمینان میدهد که استراتژی جستجو هم حساس و هم خاص است. به عنوان مثال، استفاده از “AND” جستجو را محدود می کند تا فقط نتایج حاوی هر دو عبارت را شامل شود، در حالی که “OR” آن را برای شامل نتایج حاوی هر یک از عبارت ها گسترش می دهد.
هنگام انجام این جستجوها، ترکیب مرور متون (انتشارات) با دوره های جستجوی سیستماتیک متمرکزتر مهم است. این فرآیند تکراری اجازه می دهد تا جستجو با پیشرفت مرور تکامل یابد.
توجه به این نکته ضروری است که این اطلاعات ممکن است کاملاً جامع و به روز نباشد.
مثال:
مطالعات با جستجوی PubMed، PsycINFO و کتابخانه کاکرین شناسایی شدند. ما جستجوهایی را برای مطالعات منتشر شده بین اولین سال موجود و ۱ آوریل ۲۰۰۹، با استفاده از عبارت جستجوی تمرکز حواس همراه با عبارات مدیتیشن، برنامه، درمان، یا مداخله و اضطراب (anxi)، افسردگی (depress)، خلق و خو یا استرس انجام دادیم. علاوه بر این، یک بررسی دستی گسترده از فهرست های مرجع مطالعات مرتبط و مقالات مروری استخراج شده از جستجوهای پایگاه داده انجام شد. مقالاتی که مشخص شد مرتبط با موضوع ذهن آگاهی هستند برای بررسی بیشتر انتخاب شدند.
معیارهای واجد شرایط بودن
معیارهای ورود و خروج را برای بررسی مشخص کنید.
قبل از شروع جستجوی متون، محققان باید معیارهای واجد شرایط بودن را برای ورود به مطالعه تعیین کنند.
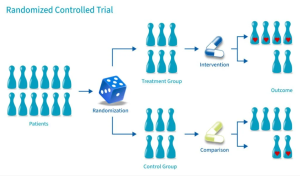
برای حفظ شفافیت و به حداقل رساندن سوگیری، معیارهای واجد شرایط بودن برای ورود به مطالعه باید از پیش تعیین شود. در حالت ایدهآل، محققان باید هدفشان این باشد که فقط کارآزماییهای تصادفیسازی و کنترلشده با کیفیت بالا را شامل شوند که به اصل قصد درمان پایبند باشند.
انتخاب مطالعات نباید خودسرانه باشد و منطق پشت معیارهای ورود و خروج باید به وضوح در پروتکل تحقیق بیان شود.
هنگام تعیین معیارهای ورود و خروج، جنبه های زیر را در نظر بگیرید:
مثال:
مطالعات در صورتی انتخاب شدند که (الف) شامل موارد ذیل بودند: مداخله مبتنی بر ذهن آگاهی، (ب) یک نمونه بالینی (یعنی شرکت کنندگان یک اختلال روانی یا جسمی/پزشکی قابل تشخیص داشتند)، (ج) بزرگسالان (18 تا 65 سال بودند)، (د) برنامه ذهن آگاهی با درمان مبتنی بر پذیرش و تعهد یا رفتار درمانی دیالکتیکی همراه نبود، (ه) آنها معیاری از اضطراب و/یا علائم خلقی را در قبل و بعد از مداخله در نظر گرفتند، و (و) آنها داده های کافی برای انجام تجزیه و تحلیل اندازه اثر (به عنوان مثال، میانگین ها و انحرافات استاندارد، مقادیر t یا F، امتیازات تغییر، فراوانی ها، یا سطوح احتمال) ارائه می کردند. در صورتی که نمونه به طور جزئی یا کامل با نمونه مطالعه دیگری مطابق با معیارهای ورود به متاآنالیز همپوشانی داشته باشد، مطالعات حذف شدند. در این موارد، ما مطالعه با حجم نمونه بزرگتر یا داده های کامل تر برای اندازه گیری علائم اضطراب و افسردگی را لحاظ کردیم. برای مطالعاتی که دادههای ناکافی ارائه میکردند، اما همچنان برای تجزیه و تحلیل مناسب بودند، نویسندگان برای داده های تکمیلی تماس گرفتند.
فرآیند تکرار شونده
ماهیت تکراری توسعه استراتژی جستجو از نیاز به پالایش و انطباق فرآیند جستجو بر اساس اطلاعاتی که در هر مرحله با آن مواجه میشویم ناشی میشود.
یک تلاش واحد به ندرت به یک استراتژی نهایی کامل منجر می شود. در عوض، این یک فرآیند در حال تکامل است که شامل یک سری جستجوهای آزمایشی، تجزیه و تحلیل نتایج و بحث در میان تیم بررسی میشود.
روند تکرار به صورت زیر است:
با اصلاح مداوم استراتژی جستجو بر اساس نتایج و بازخورد، محققان می توانند اطمینان بیشتری داشته باشند که همه مطالعات مرتبط را شناسایی کرده اند.
این فرآیند تکراری تضمین میکند که استراتژی جستجوی اعمال شده به اندازه کافی حساس است تا تمام مطالعات مربوطه را ثبت کند و در عین حال دامنه قابل مدیریتی را حفظ کند.
در طول این فرآیند، مستندسازی دقیق استراتژی جستجو، از جمله هرگونه تغییر، برای شفافیت و تکرار متاآنالیز در آینده بسیار مهم است.
جستجو یک فعالیت عملی است: اگر یک جستجو 15000 مورد را شناسایی کند و تیم بررسی متشکل از دو نفر باشد که در اوقات فراغت خود کار می کنند، ممکن است لازم باشد که دامنه بررسی و معیارهای گنجاندن محدود شود. این کار را می توان با تجدید نظر در تاریخ انتشار (به عنوان مثال، مقالات منتشر شده در ده سال گذشته، به جای 20 سال)، و/یا جمعیت و/یا طرح های مطالعه مورد علاقه انجام داد.
مرحله 3: جستجو در ادبیات
جستجوی سیستماتیک متون را با استفاده از عبارات جستجو و پایگاه داده به وضوح تعریف شده انجام دهید.
بکارگیری استراتژی جستجو شامل وارد کردن رشته های جستجوی ساخته شده در رابط های جستجوی پایگاه های داده مربوطه است. این رشته های جستجو، که با استفاده از عملگرهای بولی، نمادهای برش، حروف عام، و نحو خاص پایگاه داده ایجاد شده اند، با هدف بازیابی همه مطالعات مرتبط بالقوه مرتبط با سوال تحقیق می باشند.
محقق در این مرحله با ویژگی های پایگاه داده تعامل می کند تا جستجو را اصلاح کند و نتایج بازیابی شده را مدیریت کند.
این کار ممکن است شامل استفاده از فیلترهای جستجوی ارائه شده توسط پایگاه داده برای تمرکز بر طرح های مطالعه خاص، انواع انتشارات، یا سایر پارامترهای مرتبط باشد.
بکارگیری استراتژی جستجو صرفاً یک فرآیند مکانیکی برای وارد کردن عبارات نیست. این نیاز به درک کامل از عملکردهای پایگاه داده و یک چشم فهیم برای تنظیم جستجو بر اساس ماهیت نتایج بازیابی شده دارد.
مرحله 4: غربالگری و انتخاب مقالات پژوهشی
پس از تکمیل جستجوی ادبیات، گام بعدی غربالگری و انتخاب مطالعاتی است که در متاآنالیز گنجانده می شوند.
این شامل بررسی دقیق هر مطالعه برای تعیین ارتباط آن با سؤال تحقیق و کیفیت روش شناختی آن است.
هدف شناسایی مطالعاتی است که هم مرتبط با سوال تحقیق هستند و هم کیفیت کافی برای کمک به یک سنتز معنادار دارند.
مطالعاتی که دارای معیارهای واجد شرایط بودن هستند معمولاً در پایگاههای اطلاعاتی الکترونیکی مانند Endnote یا Mendeley ذخیره میشوند و شامل عنوان، نویسندگان، تاریخ و مجله چاپ به همراه یک چکیده (در صورت وجود) میشوند.
فرآیند انتخاب
روشهای مورد استفاده برای تصمیمگیری را مشخص کنید که آیا یک مطالعه با معیارهای ورود به بررسی مطابقت دارد، از جمله اینکه چه تعداد بازبین هر رکورد و هر گزارش بازیابی شده را غربال میکنند، آیا آنها مستقل کار میکنند یا خیر، و در صورت امکان، جزئیات ابزارهای اتوماسیون مورد استفاده در این فرآیند.
فرآیند انتخاب در یک متاآنالیز شامل چندین بازبین برای اطمینان از دقت و قابلیت اطمینان است.
دو داور باید به طور مستقل عناوین و چکیده ها را بررسی کنند و مطالعات تکراری و نامربوط را بر اساس معیارهای ورود و خروج از پیش تعریف شده حذف کنند.
نمودار جریان PRISMA
نمودار جریان PRISMA یک نمایش بصری از فرآیند انتخاب مطالعه در یک بررسی سیستماتیک است.
فلوچارت، روند گام به گام غربالگری، فیلتر کردن و انتخاب مطالعات بر اساس معیارهای ورود و خروج از پیش تعریف شده را نشان می دهد.
فلوچارت به صورت بصری مراحل زیر را نشان می دهد:
این رویکرد سیستماتیک و شفاف، همانطور که در نمودار جریان PRISMA تجسم شده است، فرآیند انتخاب قوی و بیطرفانه را تضمین میکند و قابلیت اطمینان یافتههای بررسی سیستماتیک را افزایش میدهد.
فلوچارت به عنوان یک رکورد بصری از تصمیمات اتخاذ شده در طول فرآیند انتخاب مطالعه عمل می کند و به خوانندگان اجازه می دهد تا دقت و جامعیت بررسی را ارزیابی کنند.

مرحله 5: ارزیابی کیفیت مطالعات
فرآیند جمع آوری داده ها
روشهای مورد استفاده برای جمعآوری دادهها از گزارشها را مشخص کنید، از جمله اینکه چه تعداد از مرورگران دادهها را از هر گزارش جمعآوری کردهاند، اینکه آیا آنها به طور مستقل کار میکردند، و هر فرآیندی برای به دست آوردن یا تأیید دادهها از محققان مطالعه، و در صورت امکان، جزئیات ابزارهای اتوماسیون مورد استفاده در این فرآیند.
استخراج دادهها بر اطلاعات مرتبط با سؤال تحقیق، مانند عوامل خطر یا بازیابی مربوط به یک پدیده خاص متمرکز است.
استخراج داده های مرتبط با سوال تحقیق، مانند اندازه اثر، اندازه نمونه، میانگین، انحراف معیار و سایر معیارهای آماری.
تمرکز بر تفسیرهای نویسندگان از یافتهها به جای نقل قولهای تک تک شرکتکنندگان میتواند مفید باشد، زیرا مورد دوم فاقد بستر کامل دادههای اصلی است.
کدگذاری مطالعات
کدگذاری مطالعات در یک متاآنالیز شامل استخراج دقیق و سیستماتیک داده ها از هر مطالعه شامل به روشی استاندارد و قابل اعتماد است. این مرحله برای اطمینان از صحت و اعتبار یافته های متاآنالیز ضروری است.
سپس از این اطلاعات برای محاسبه اندازه اثر، بررسی تعدیلکنندگان بالقوه و نتیجهگیری کلی استفاده میشود.
رویههای کدگذاری معمولاً شامل ایجاد یک فرم رکورد استاندارد یا پروتکل کدگذاری است. این فرم استخراج داده ها از هر مطالعه را به شیوه ای سازگار و سازمان یافته هدایت می کند. دو ناظر مستقل می توانند به اطمینان از دقت و به حداقل رساندن خطاها در طول استخراج داده ها کمک کنند.
فراتر از اطلاعات اولیه مانند نویسندگان و سال انتشار، ویژگی های مهم و کلیدی مرتبط با سؤال تحقیق را کدگذاری کنید.
به عنوان مثال، اگر متاآنالیز بر روی اثرات یک درمان خاص متمرکز شود، ویژگی های مربوط به کد ممکن است شامل موارد زیر باشد:
قبل از اعمال پروتکل کدگذاری برای همه مطالعات، تست آزمایشی آن در زیر مجموعه کوچکی از مطالعات بسیار مهم است. این امر به شناسایی هرگونه ابهام، ناسازگاری یا زمینه هایی برای بهبود در پروتکل کدگذاری قبل از شروع کدگذاری در مقیاس کامل کمک می کند.
مواجهه با داده های گمشده یا غائب (missing) در مقالات تحقیقات اولیه معمول است. یک استراتژی واضح برای مدیریت دادههای گمشده ایجاد کنید، که ممکن است شامل تماس با نویسندگان مطالعه، استفاده از روشهای انتساب یا انجام تحلیلهای حساسیت برای ارزیابی تأثیر دادههای از دست رفته بر نتایج کلی باشد.
ابزارهای ارزیابی کیفیت
محققان از ابزارهای استاندارد شده برای ارزیابی کیفیت و خطر سوگیری در مطالعات کمی موجود در متاآنالیز استفاده میکنند. برخی از ابزارهای رایج عبارتند از:
1. ابزار خطر سوگیری کاکرین:
2. مقیاس نیوکاسل-اتاوا (NOS):
3. ابزار ROBINS-I (خطر سوگیری در مطالعات غیرتصادفی – مداخلات):
4. QUADAS (ارزیابی کیفیت مطالعات دقت تشخیصی):
با استفاده از این ابزارها، محققان می توانند اطمینان حاصل کنند که مطالعاتی که در متاآنالیز آنها گنجانده شده است از کیفیت روش شناختی بالایی برخوردار است و داده های کمی قابل اعتماد را به تحلیل کلی کمک می کند.
مرحله 6: انتخاب اندازه اثر
انتخاب متریک اندازه اثر معمولاً با سؤال تحقیق و ماهیت متغیر وابسته تعیین می شود.
ممکن است برای تبدیل یافتههای گزارششده به اندازه اثر اولیه انتخابی، تبدیل اندازههای اثر به یک معیار رایج ضروری باشد. هدف هماهنگ کردن اندازههای مختلف اندازه اثر با یک معیار مشترک برای مقایسه و تحلیل معنادار است.
این تبدیل به محققان اجازه می دهد تا مطالعاتی را شامل شوند که یافته ها را با استفاده از معیارهای اندازه اثر مختلف گزارش می دهند. به عنوان مثال، r را می توان تقریباً به d تبدیل کرد، و بالعکس، با استفاده از معادلات خاص. به طور مشابه، r را می توان از یک نسبت شانس با استفاده از فرمول دیگری استخراج کرد.
بسیاری از معادلات مربوط به تبدیل اندازه اثر را می توان در روزنتال (1991) یافت.
مرحله 7: ارزیابی ناهمگونی
ناهمگونی به تغییر در اندازه اثر در مطالعات پس از محاسبه خطاهای نمونه گیری درون مطالعه اشاره دارد.
ناهمگونی به میزان تفاوت نتایج (اندازه اثر) بین مطالعات مختلف اشاره دارد، جایی که هیچ گونه تغییری به این معنی است که همه مطالعات بهبود یکسانی (بدون ناهمگونی) را نشان میدهند، در حالی که تنوع بیشتر نشاندهنده ناهمگونی بیشتر است.
ارزیابی ناهمگونی اهمیت دارد زیرا به ما کمک می کند بفهمیم که آیا مداخله مطالعه به طور منسجم در زمینه های مختلف کار می کند و نحوه ترکیب و تفسیر نتایج مطالعات متعدد را راهنمایی می کند.
در حالی که ناهمگونی اندک به ما امکان می دهد در نتیجه گیری کلی خود مطمئن تر باشیم، ناهمگونی قابل توجه نیاز به بررسی بیشتر در مورد علل اساسی آن دارد.
نحوه ارزیابی ناهمگونی
مرحله 8: انتخاب مدل فرا تحلیلی
متاآنالیزورها با انتخاب بین مدل های تحلیلی اثرات ثابت و اثرات تصادفی به ناهمگنی می پردازند.
اگر ناهمگنی زیاد است، از مدل اثرات تصادفی استفاده کنید. اگر ناهمگنی کم است، یا اگر همه مطالعات از نظر عملکردی یکسان هستند و شما به دنبال تعمیم به طیفی از سناریوها نیستید، از یک مدل اثر ثابت استفاده کنید.
اگرچه یک آزمون آماری برای همگنی میتواند به ارزیابی تنوع در اندازههای اثر در مطالعات کمک کند، اما نباید انتخاب بین مدلهای اثرات ثابت و تصادفی را تعیین کند.
تصمیم گیری در مورد اینکه کدام مدل استفاده شود در نهایت یک تصمیم مفهومی است که توسط درک محقق از زمینه تحقیق و اهداف فراتحلیل هدایت می شود.
اگر تعداد مطالعات محدود باشد، تجزیه و تحلیل اثرات ثابت مناسب تر است، در حالی که مطالعات بیشتری برای برآورد پایدار واریانس بین مطالعات در یک مدل اثرات تصادفی مورد نیاز است.
توجه به این نکته مهم است که استفاده از مدل اثرات تصادفی به طور کلی یک رویکرد محافظه کارانه تر است.
مدل های با اثرات ثابت
مدلهای اثرات ثابت فرض میکنند که یک اندازه اثر واقعی زیربنای همه مطالعات وجود دارد. هدف برآورد این اندازه اثر مشترک با بیشترین دقت است که با به حداقل رساندن درون مطالعه (نمونه گیری) به دست می آید.
در نتیجه، مطالعات بر اساس معکوس واریانس آنها وزن داده می شود.
این یعنی مطالعات بزرگتر، که عموماً واریانس های کوچکتری دارند، وزن بیشتری در تجزیه و تحلیل به خود اختصاص می دهند زیرا تخمین های دقیق تری از اندازه اثر مشترک ارائه می کنند.
جوانب مثبت:
معایب:
مدلهای اثرات تصادفی
مدلهای اثرات تصادفی فرض میکنند که اندازه اثر واقعی میتواند در مطالعات مختلف متفاوت باشد. هدف در اینجا تخمین میانگین این اندازههای اثر متغیر است، با در نظر گرفتن واریانس درون مطالعه و واریانس بین مطالعه (ناهمگونی).
این رویکرد تصدیق میکند که هر مطالعه ممکن است اندازه اثر کمی متفاوت را به دلیل عواملی فراتر از خطای نمونهگیری، مانند تغییرات در جمعیتهای مطالعه، مداخلات، یا طرحها تخمین بزند.
این وزن دهی متعادل از تأثیر نامتناسب مطالعات بزرگ بر تخمین اندازه اثر کلی جلوگیری می کند، که منجر به یک میانگین اندازه اثر نماینده بیشتر می شود که منعکس کننده توزیع اثرات در طیف وسیعی از مطالعات است.
جوانب مثبت:
معایب:
مرحله 9: متاآنالیز را انجام دهید.
این مرحله شامل ترکیب آماری اندازه اثر از مطالعات انتخاب شده است. متاآنالیز از میانگین وزنی اندازه اثر استفاده می کند، که معمولاً به مطالعات دقیق تر (اغلب آنهایی که اندازه نمونه بزرگتر دارند) وزن بیشتری می دهد.
عملکرد اصلی متاآنالیز تخمین اثرات در یک جمعیت با ترکیب اندازه اثر از چندین مقاله است.
این طرح وزن دهی از نظر آماری منطقی است زیرا اندازه اثر با دقت نمونه گیری خوب (یعنی احتمالاً بازتاب دقیقی از واقعیت است) وزن بالایی دارد.
از سوی دیگر، اندازه اثر از مطالعاتی که دقت نمونهگیری پایینتر دارند، وزن کمتری در محاسبات دریافت می کنند.
فرآیند:
تخمین اندازه اثر با استفاده از اثرهای ثابت
مدل اثرات ثابت در متاآنالیز با این فرض عمل می کند که همه مطالعات وارد شده، اندازه اثر واقعی یکسانی را تخمین می زنند.
این مدل در هنگام تعیین وزن هر مطالعه صرفاً بر واریانس درون مطالعه تمرکز دارد.
وزن به عنوان معکوس واریانس درون مطالعه محاسبه میشود که معمولاً منجر به دریافت وزن قابل ملاحظهای بیشتر در مطالعات بزرگتر در تجزیه و تحلیل میشود.
این رویکرد مبتنی بر این ایده است که مطالعات بزرگتر برآوردهای دقیق تری از اثر واقعی ارائه می دهند.
میانگین وزنی اندازه اثر (M) با جمع کردن خروجی های اندازه اثر هر مطالعه (ESi) و وزن متناظر آن (wi) و تقسیم آن مجموع بر مجموع کل وزنها محاسبه میشود:
1. محاسبه وزن (wi) برای هر مطالعه:
وزن اغلب معکوس واریانس اندازه اثر است. این بدان معناست که مطالعات با حجم نمونه بزرگتر و تنوع کمتر وزن بیشتری خواهند داشت، زیرا تخمین های دقیق تری از اندازه اثر ارائه می کنند.
این طرح وزن دهی این فرض را در یک مدل اثر ثابت منعکس می کند که همه مطالعات اندازه اثر واقعی یکسانی را تخمین می زنند و هر گونه تفاوت مشاهده شده در اندازه اثر صرفاً به دلیل خطای نمونه گیری است. بنابراین، مطالعات با خطای نمونهگیری کمتر (یعنی واریانسهای کوچکتر) قابل اعتمادتر در نظر گرفته میشوند و وزن بیشتری در تجزیه و تحلیل داده میشوند.
در اینجا فرمول محاسبه وزن در متاآنالیز با اثر ثابت آمده است:
Wi = 1 / VYi1
Wi نشان دهنده وزن اختصاص داده شده برای مطالعه i است.
VYi واریانس درون مطالعه برای مطالعه i است.
مراحل عملی:
وزن برای هر مطالعه به صورت زیر محاسبه می شود: وزن = 1 / (واریانس درون مطالعه)
به عنوان مثال: فرض کنید یک مطالعه واریانس درون مطالعه 0.04 را گزارش می کند. وزن برای این مطالعه: 1 / 0.04 = 25 خواهد بود
وزن هر مطالعه ای را که در متاآنالیز شما گنجانده شده است با استفاده از این روش محاسبه کنید.
این وزن ها در محاسبات بعدی، مانند محاسبه اندازه اثر میانگین وزنی، استفاده خواهند شد.
توجه: در یک مدل اثرات ثابت، ما τ² (مربع tau) را محاسبه یا استفاده نمی کنیم، که نشان دهنده واریانس بین مطالعه است. این فقط در مدل های اثرات تصادفی استفاده می شود.
2. تأثیر هر مطالعه را در وزن آن ضرب کنید:
پس از محاسبه وزن هر مطالعه، اندازه اثر را در وزن متناظر آن ضرب کنید. این مرحله بسیار مهم است زیرا تضمین میکند که مطالعات با تخمین اندازه اثر دقیقتر به طور متناسب بیشتر به میانگین وزنی اندازه اثر کلی کمک میکنند.
برای هر مطالعه، اندازه اثر آن را در وزنی که تازه محاسبه کردیم ضرب کنید.
3. تمام این اثرات وزنی را جمع کنید:
تمام محصولات مرحله 2 را جمع بزنید.
4. تقسیم بر مجموع همه اوزان:
تمام وزن هایی را که در مرحله 1 محاسبه کردیم جمع کنید.
مجموع مرحله 3 را بر وزن کل تقسیم کنید.
پیامدهای مدل اثرات ثابت
تخمین اندازه اثر با استفاده از اثرهای تصادفی
متاآنالیز اثرات تصادفی کمی پیچیدهتر است زیرا منابع متعددی از تفاوتها که به طور بالقوه بر اندازه اثر تأثیر میگذارند باید در نظر گرفته شوند.
تفاوت اصلی در مدل اثرات تصادفی، گنجاندن τ² (مربع تاو) در محاسبه وزن است. این امر ناهمگونی بین مطالعات را نشان میدهد، با توجه به اینکه مطالعات ممکن است اثرات متفاوتی را اندازهگیری کنند.
این فرآیند منجر به یک اندازه اثر کلی میشود که هم تنوع درون مطالعه و هم تنوع بین مطالعه را در نظر میگیرد و زمانی که مطالعات در روشها یا جمعیتها متفاوت هستند مناسبتر است.
مدل واریانس اندازههای اثر واقعی (τ²) را تخمین میزند. این به تعداد معقولی از مطالعات نیاز دارد، بنابراین تخمین اثرات تصادفی ممکن است با مطالعات بسیار کمی امکان پذیر نباشد.
تخمین معمولاً با استفاده از نرم افزارهای آماری انجام می شود و حداکثر احتمال محدود شده (REML) یک روش رایج است.
1. محاسبه وزن برای هر مطالعه:
در یک متاآنالیز با اثرات تصادفی، وزن اختصاص داده شده به هر مطالعه (W*i) به عنوان معکوس واریانس آن مطالعه، مشابه یک مدل اثر ثابت، محاسبه میشود. با این حال، واریانس در یک مدل اثرات تصادفی هم واریانس درون مطالعه (VYi) و هم واریانس بین مطالعات (T^2) را در نظر می گیرد.
گنجاندن T^2 در مخرج فرمول وزن منعکس کننده فرض مدل اثرات تصادفی است که اندازه اثر واقعی می تواند در مطالعات متفاوت باشد.
این بدان معنی است که علاوه بر خطای نمونه گیری، منبع دیگری از تنوع وجود دارد که باید در وزن دهی مطالعات در نظر گرفته شود. واریانس بین مطالعات، T^2، این منبع اضافی تنوع را نشان می دهد.
فرمول محاسبه وزن در متاآنالیز با اثرات تصادفی در اینجا آمده است:
W*i = 1 / (VYi + T^2)
W*i وزن اختصاص داده شده به مطالعه i را نشان می دهد.
VYi واریانس درون مطالعه برای مطالعه i است.
T^2 واریانس بین مطالعات برآورد شده است.
مراحل عملی:
ابتدا باید چیزی به نام τ² (tau مربع) محاسبه کنیم. این نشان دهنده واریانس بین مطالعه است.
تخمین T^2 را میتوان با استفاده از روشهای مختلفی انجام داد، یکی از روشهای رایج روش گشتاورها (روش DerSimonian و Laird) است.
فرمول T^2 با استفاده از روش گشتاورها به این صورت است: T^2 = (Q – df) / C
Q آماره همگنی است.
df درجات آزادی است (تعداد مطالعات -1).
C یک ثابت است که بر اساس وزن های مورد مطالعه محاسبه می شود
سپس وزن هر مطالعه به صورت زیر محاسبه میشود: وزن = 1 / (واریانس درون مطالعه + τ²). این با مدل جلوههای ثابت متفاوت است، زیرا ما τ² را اضافه میکنیم تا تغییرات بین مطالعات را محاسبه کنیم.
2. تأثیر هر مطالعه را در وزن آن ضرب کنید:
برای هر مطالعه، اندازه اثر آن را در وزنی که تازه محاسبه کردیم ضرب کنید.
3. تمام این اثرات وزنی را جمع کنید:
تمام محصولات مرحله 2 را جمع کنید.
4. تقسیم بر مجموع همه اوزان:
تمام وزن هایی را که در مرحله 1 محاسبه کردیم جمع کنید. مجموع مرحله 3 را بر وزن کل تقسیم کنید.
پیامدهای مدل اثرات تصادفی
مرحله 10: تحلیل حساسیت
استحکام یافته های خود را با تکرار تجزیه و تحلیل با استفاده از روش های آماری مختلف، مدل ها (اثرات ثابت و تصادفی) یا معیارهای ورود ارزیابی کنید. این به تعیین حساسیت نتایج شما به انتخاب های انجام شده در طول فرآیند کمک می کند.
تحلیل حساسیت یک متاآنالیز را با آشکار ساختن میزان قوی بودن یافته ها برای تصمیمات و فرضیات مختلف در طول فرآیند تقویت می کند. این کمک می کند تا مشخص شود که آیا نتایج حاصل از متاآنالیز زمانی که از روش ها، معیارها یا زیرمجموعه های مختلف داده استفاده می شود، پابرجا هستند یا خیر.
این امر به ویژه مهم است زیرا ممکن است نظرات در مورد بهترین رویکرد برای انجام یک متاآنالیز متفاوت باشد و کاوش در این تغییرات بسیار مهم است.
در اینجا چند روش کلیدی وجود دارد که تجزیه و تحلیل حساسیت به یک متاآنالیز قوی تر کمک می کند:
با تغییر سیستماتیک جنبههای مختلف متاآنالیز، محققان میتوانند استحکام یافتههای خود را ارزیابی کنند و نگرانیهای بالقوه در مورد اعتبار نتیجهگیریهای خود را برطرف کنند.
این فرآیند ترکیب قابل اعتمادتری از شواهد تحقیق را تضمین می کند.
اشتباهات رایج در متاآنالیز
هنگام انجام یک متاآنالیز، چندین مشکل رایج ممکن است ایجاد شود که به طور بالقوه اعتبار و قابلیت اطمینان یافته ها را تضعیف می کند. منابع در برابر این اشتباهات احتیاط می کنند و راهنمایی هایی را برای انجام متاآنالیزهای صحیح روش شناختی ارائه می دهند.
مطالب مرتبط مفید



پاسخگوی سوالات و نظرات شما هستیم