نمونه گیری تصادفی ساده
763 Views
از اصلی ترین تکنیکهای آماری مورد استفاده در بخش مواد و روش های مقاله باید به نمونه گیری تصادفی ساده اشاره کنیم. شاید برایتان سوال باشد چگونه می توانید نمونه ای را انتخاب کنید که واقعاً تصادفی و نماینده جامعه شرکت کننده باشد؟ نمونه گیری تصادفی ساده روش نمونه گیری است که این امر را آسان می کند. نحوه کارکرد آن را در این مقاله آموزشی خواهید آموخت.
تعریف – نمونه گیری تصادفی ساده چیست؟ نمونه گیری تصادفی ساده یک گروه کوچکتر (نمونه) را از یک گروه بزرگتر از تعداد کل شرکت کنندگان (جامعه) انتخاب می کند. این یکی از ساده ترین روش های نمونه گیری سیستماتیک است که برای به دست آوردن یک نمونه تصادفی استفاده می شود. این تکنیک متکی بر استفاده از روش انتخابی است که به هر شرکت کننده شانس یا احتمال مساوی برای انتخاب شدن می دهد. از آنجایی که فرآیند انتخاب بر اساس احتمال و انتخاب تصادفی است، نمونه نهایی کوچکتر به احتمال زیاد نماینده کل جامعه و عاری از سوگیری یا bias محقق است. به این روش روش شانس نیز گفته می شود.
نمونه گیری تصادفی ساده یکی از چهار روش نمونه گیری احتمالی است: نمونه گیری تصادفی ساده، نمونه گیری سیستماتیک، نمونه گیری طبقه ای و نمونه گیری خوشه ای.
فرآیند نمونه گیری تصادفی ساده
- اندازه جمعیتی که با آن کار می کنید را مشخص کنید که می تواند بر اساس جمعیت یک شهر باشد. برای این تمرین، اندازه جمعیت 1000 را در نظر می گیریم.
- یک عدد متوالی تصادفی را به هر یک از شرکت کنندگان در جمعیت اختصاص دهید، که به عنوان یک شماره شناسه عمل می کند – به عنوان مثال. 1، 2، 3، 4، 5 و غیره تا 1000.
- تعداد اندازه نمونه مورد نیاز را تعیین کنید. در مورد اندازه نمونه مناسب مطمئن نیستید؟ ماشین حساب اندازه نمونه را امتحان کنید (https://www.qualtrics.com/blog/calculating-sample-size/ ).
برای این تمرین، از 100 به عنوان حجم نمونه استفاده می کنیم.
- نمونه خود را با اجرای یک مولد اعداد تصادفی انتخاب کنید تا 100 عدد تصادفی تولید شده از 1 تا 1000 ارائه شود.
چرا از نمونه گیری تصادفی ساده استفاده می کنیم؟
نمونه گیری تصادفی ساده معمولاً در جایی استفاده می شود که اطلاعات کمی در مورد جمعیت شرکت کنندگان وجود داشته باشد. محققان همچنین باید مطمئن شوند که روشی برای برقراری ارتباط با هر یک از شرکتکنندگان دارند تا بتوانند به اندازه واقعی جمعیت برسند که به جهان بیرون نزدیک باشد. این منجر به چندین مزیت و عیب می شود که حتما باید در نظر داشت.
مزایای نمونه گیری تصادفی ساده
این روش نمونه گیری می تواند مزایای بزرگی را به همراه داشته باشد.
شرکت کنندگان شانس برابر و منصفانه ای برای انتخاب شدن دارند. از آنجایی که روش انتخاب استفاده شده به هر شرکت کننده شانس منصفانه ای می دهد، نمونه حاصل بی طرف است و تحت تأثیر تیم تحقیق قرار نمی گیرد. در واقع برای آزمایش های کور عالی است.
این تکنیک همچنین نتایج تصادفی را از یک استخر بزرگتر (larger pool) ارائه می دهد. نمونه کوچکتر به دست آمده باید نماینده کل جمعیت شرکت کنندگان باشد، به این معنی که نیازی به تقسیم بندی بیشتر برای اصلاح گروه ها نیست.
در نهایت، این روش ارزان، سریع و آسان برای انجام است – زمانی عالی است که می خواهید پروژه تحقیقاتی خود را به سرعت شروع کنید.
معایب نمونه گیری تصادفی ساده
ممکن است مواردی وجود داشته باشد که انتخاب تصادفی منجر به یک نمونه واقعا تصادفی نشود. خطاهای نمونه گیری ممکن است منجر به انتخاب شرکت کنندگان مشابه شود، در حالی که نمونه نهایی کل جامعه را منعکس نمی کند.
در ضمن، این روش هیچ کنترلی برای محقق فراهم نمی کند تا بتواند نتایج را بدون سوگیری تحت تأثیر قرار دهد. در این موارد، تکرار فرآیند انتخاب، منطقی ترین راه حل مسئله است.
از چه روش های انتخابی می توانید استفاده کنید؟
قرعه کشی مثال خوبی از نمونه گیری تصادفی ساده در محل کار است. شما مجموعه اعداد خود را انتخاب می کنید، یک بلیط می خرید و امیدوارید که اعداد شما با توپ های لوتو که به طور تصادفی انتخاب شده اند مطابقت داشته باشد. بازیکنان با اعداد منطبق برندگان هستند که نشان دهنده نسبت کمی از شرکت کنندگان برنده از تعداد کل بازیکنان هستند.
سایر روشهای انتخاب مورد استفاده شامل ناشناس کردن جمعیت است – به عنوان مثال، با اختصاص دادن یک عدد به هر مورد یا فرد در جمعیت – و سپس انتخاب اعداد به صورت تصادفی.
محققان میتوانند با قرار دادن نام همه شرکتکنندگان در یک کلاه و انتخاب نامها برای تشکیل نمونه کوچکتر، از نسخه سادهتری از این حالت استفاده کنند.
مقایسه نمونهگیری تصادفی ساده با سه روش نمونهگیری احتمالی دیگر
سه نوع دیگر از تکنیکهای نمونهگیری احتمالی شباهتها و تفاوتهای واضحی با نمونهگیری تصادفی ساده دارند:
نمونه گیری سیستماتیک
نمونهگیری سیستماتیک یا خوشهبندی سیستماتیک، یک روش نمونهگیری مبتنی بر نمونهگیری فاصلهای است – انتخاب شرکتکنندگان در فواصل زمانی ثابت.
به همه شرکت کنندگان یک شماره اختصاص داده می شود. یک نقطه شروع تصادفی برای انتخاب اولین شرکت کننده تصمیم گرفته می شود. یک عدد بازه زمانی تعریف شده بر اساس حجم کل نمونه مورد نیاز از جامعه انتخاب می شود که برای هر n امین شرکت کننده پس از اولین شرکت کننده اعمال می شود.
به عنوان مثال، محقق به طور تصادفی نفر پنجم جامعه را انتخاب می کند. یک بازه معادل 3 انتخاب می شود، بنابراین نمونه با شرکت کنندگان 8، 11، 14، 17، 20م (و غیره) پس از اولین انتخاب پر می شود.
از آنجایی که نقطه شروع اولین شرکت کننده تصادفی است، انتخاب بقیه نمونه به صورت تصادفی در نظر گرفته می شود.
نمونه گیری تصادفی ساده با نمونه گیری سیستماتیک متفاوت است زیرا نقطه شروع مشخصی وجود ندارد. این بدان معنی است که انتخاب ها می توانند از هر نقطه ای در سراسر جمعیت باشند و ممکن است خوشه های احتمالی ایجاد شوند.
نمونه گیری طبقه ای
نمونهگیری طبقهای، یک جمعیت را بر اساس تفاوتهای بین ویژگیهای مشترک، به گروهها یا اقشار از پیش تعریفشده تقسیم میکند. نژاد، جنسیت، ملیت. نمونه گیری تصادفی در هر یک از این گروه ها انجام می شود.
این روش نمونهگیری اغلب زمانی استفاده میشود که محققان از زیرشاخههای موجود در یک جمعیت آگاه باشند که باید در تحقیق در نظر گرفته شوند – به عنوان مثال، تحقیق در مورد تقسیم جنسیتی در دستمزدها مستلزم تمایز بین شرکت کنندگان زن و مرد در نمونه است.
نمونه گیری تصادفی ساده با نمونه گیری طبقه ای متفاوت است زیرا انتخاب از کل جمعیت بدون توجه به ویژگی های مشترک انجام می شود. در حالی که محققان استدلال خود را برای طبقه بندی جامعه به کار می برند که منجر به سوگیری بالقوه می شود، هیچ ورودی از سوی محققان در نمونه گیری تصادفی ساده وجود ندارد.
نمونه گیری خوشه ای
نمونه گیری خوشه ای به دو صورت یک مرحله ای و دو مرحله ای انجام می شود.
نمونه گیری خوشه ای یک مرحله ای ابتدا گروه ها یا خوشه هایی را از جمعیت شرکت کنندگان ایجاد می کند که کل جمعیت را نشان می دهد. این گروه ها بر اساس گروه بندی های قابل مقایسه ای هستند که وجود دارند – به عنوان مثال، کدهای پستی، مدارس یا شهرها.
خوشه ها به صورت تصادفی انتخاب می شوند و سپس نمونه گیری در این خوشه های انتخاب شده انجام می شود. ممکن است خوشه های زیادی وجود داشته باشد که متقابلاً منحصر به فرد هستند، بنابراین شرکت کنندگان بین گروه ها همپوشانی ندارند.
نمونه گیری خوشه ای دو مرحله ای ابتدا به طور تصادفی خوشه را انتخاب می کند، سپس شرکت کنندگان به طور تصادفی از درون آن خوشه انتخاب می شوند.
نمونهگیری تصادفی ساده با هر دو نوع نمونهگیری خوشهای متفاوت است، زیرا انتخاب نمونه از کل جامعه انجام میشود، نه خوشهای که بهطور تصادفی انتخاب شده که کل جمعیت را نشان میدهد.
به این ترتیب، نمونهگیری تصادفی ساده میتواند نمایش وسیعتری از جامعه ارائه دهد، در حالی که نمونهگیری خوشهای تنها میتواند تصویری فوری از جامعه را از درون یک خوشه ارائه دهد.
سوالات متداول (پرسش های متداول) در مورد نمونه گیری تصادفی ساده
اگر با جمعیت زیادی کار کنم چطور؟
در جایی که حجم نمونه و جمعیت شرکتکننده زیاد است، روشهای دستی برای انتخاب با زمان و منابع موجود امکانپذیر نیست.
اینجاست که برای کمک به انجام فرآیند انتخاب تصادفی به روشهای رایانهای نیاز است – به عنوان مثال، استفاده از جداول اعداد تصادفی یا مولد اعداد تصادفی.
فرمول احتمال انتخاب شدن در نمونه چیست؟
بیایید در عمل مثال بزنیم. یک شرکت می خواهد برند نان خود را در یک منطقه بازار جدید بفروشد. اما اطلاعات کمی در مورد جمعیت دارند. جامعه 15000 نفر است و حجم نمونه 10% (1500) مورد نیاز است. با استفاده از این مثال، در اینجا به نظر می رسد که به عنوان یک فرمول:
حجم نمونه (S) = 1500
کل جمعیت (P) = 15000
احتمال قرار گرفتن در نمونه عبارت است از: (S ÷ P) x 100%
به عنوان مثال
(1,500 ÷ 15,000) x 100% = 10%
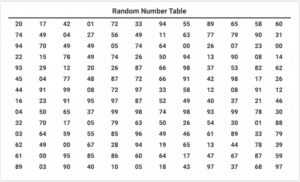
جداول اعداد تصادفی چیست؟
یکی از راه های انتخاب تصادفی اعداد استفاده از جدول اعداد تصادفی است (تصویر زیر). این اعداد متوالی کل جمعیت را از چپ به راست در جدول N تعداد ردیف و ستون قرار می دهد.
برای انتخاب تصادفی اعداد، محققین سطرها یا ستون های خاصی را برای گروه نمونه انتخاب می کنند.
چگونه می توانم اعداد تصادفی را در یک صفحه گسترده اکسل ایجاد کنم؟
برنامه صفحه گسترده اکسل مایکروسافت آفیس دارای فرمولی است که می تواند به شما در ایجاد یک عدد تصادفی کمک کند. این هست:
RAND() یک عدد تصادفی بین 1 و 0 ارائه می دهد.
برای اعداد تصادفی از کل جمعیت (به عنوان مثال، جمعیت 1000 شرکت کننده)، فرمول به روز رسانی می شود:
=INT(1000*RAND())+1
به سادگی فرمول را در سلول ها کپی و جایگذاری کنید تا به اندازه نمونه دلخواه برسید – اگر به اندازه نمونه 25 نیاز دارید، باید این فرمول را در 25 سلول قرار دهید. اعداد برگشتی بین 1 تا 1000 شماره شناسه شرکت کننده را که نمونه را تشکیل می دهند نشان می دهد.
مطالب مرتبط مفید




پاسخگوی سوالات و نظرات شما هستیم